Validating neurotransmitter colocalization in drug challenge CBF data#
[5]:
# general imports
from pathlib import Path
import pandas as pd
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
#data_dir = Path("/Volumes/ext/data/drug_mri")
[6]:
# load local nispace, for testing
# COMMENT THIS OUT IF YOU RUN THIS LOCALLY AFTER INST
import sys
sys.path.append("/Users/llotter/projects/nispace/")
Create datasets#
Data is not available for sharing. I will create a parcellated surrogate dataset in the future to share with you.
[7]:
data_dir = Path("/Users/llotter/data/drug_mri/derivatives")
dset_paths = {}
# Risperidone 0.5mg + 2mg + Placebo
base_dir = data_dir / "risp"
rand_list = pd.read_csv(base_dir / "RandomizationList.csv")
rand_list = rand_list[rand_list["Cohort Name"] == "Group A Cohort"]
rand_list["Subject ID"] = rand_list["Subject ID"].astype(str)
rand_list["Subject ID"] = rand_list["Subject ID"].str[-4:]
session_mapping = {1: "placebo", 4: "risperidone low-dose", 5: "risperidone high-dose"}
for sub_dir in sorted(list(base_dir.glob("subject*"))):
sub_id = sub_dir.name.split("_")[1]
session_ids = rand_list.loc[rand_list["Subject ID"] == sub_id, "Treatment Code"].to_list()
if len(session_ids) != 1 :
print("Problem 1", sub_dir, session_ids)
continue
session_ids = [int(i) for i in str(session_ids[0])]
session_names = [session_mapping[i] for i in session_ids]
for drug, dir_name in zip(session_names, ["visit_A", "visit_B", "visit_C"]):
# cbf
sub_file = list((sub_dir / dir_name / "cASL1").glob("wx3D_ASL_non_contrast___m.nii.gz"))
if len(sub_file) == 1:
dset_paths[("cbf", drug, sub_dir.name)] = sub_file[0]
else:
print("Problem 2", sub_file)
# rest
sub_file = list((sub_dir / dir_name / "RS").glob("swufMRI_Resting_State_m_Frist24.nii.gz"))
if len(sub_file) == 1:
dset_paths[("rest", drug, sub_dir.name)] = sub_file[0]
else:
print("Problem 2", sub_file)
dset_paths = pd.Series(dset_paths).sort_index()
dset_paths
[7]:
cbf placebo subject_1003 /Users/llotter/data/drug_mri/derivatives/risp/...
subject_1004 /Users/llotter/data/drug_mri/derivatives/risp/...
subject_1005 /Users/llotter/data/drug_mri/derivatives/risp/...
subject_1006 /Users/llotter/data/drug_mri/derivatives/risp/...
subject_1007 /Users/llotter/data/drug_mri/derivatives/risp/...
...
rest risperidone low-dose subject_1020 /Users/llotter/data/drug_mri/derivatives/risp/...
subject_1021 /Users/llotter/data/drug_mri/derivatives/risp/...
subject_1022 /Users/llotter/data/drug_mri/derivatives/risp/...
subject_1023 /Users/llotter/data/drug_mri/derivatives/risp/...
subject_1024 /Users/llotter/data/drug_mri/derivatives/risp/...
Length: 126, dtype: object
Parcellate CBF data#
[8]:
from nispace.datasets import fetch_parcellation
from nispace.io import parcellate_data
space = "MNI152NLin6Asym"
parcellation = "Schaefer400MelbourneS3"
parcellation_cx = "Schaefer400"
parcellation_sc = "MelbourneS3"
parc, parc_labels = fetch_parcellation(parcellation, return_loaded=True, space=space)
parc_cx, parc_cx_labels = fetch_parcellation(parcellation_cx, return_loaded=True, space=space)
parc_sc, parc_sc_labels = fetch_parcellation(parcellation_sc, return_loaded=True, space=space)
dset_cbf = parcellate_data(
dset_paths.loc["cbf",].to_list(),
data_labels=dset_paths.loc["cbf",].index,
data_space=space,
parcellation=parc,
parc_labels=parc_labels,
parc_space=space,
min_num_valid_datapoints=5,
min_fraction_valid_datapoints=0.1,
n_proc=-1
)
#dset_cbf.head(5)
INFO | 20/01/25 13:53:02 | nispace: Loading parcellation 'Schaefer400MelbourneS3' in 'MNI152NLin6Asym' space.
INFO | 20/01/25 13:53:02 | nispace: Loading parcellation 'Schaefer400' in 'MNI152NLin6Asym' space.
INFO | 20/01/25 13:53:02 | nispace: Schaefer400 is a cortex version of the whole-brain parcellation Schaefer400MelbourneS3.
INFO | 20/01/25 13:53:02 | nispace: Removing 50 cortical parcels and returning Nifti1 object instead of path!
INFO | 20/01/25 13:53:03 | nispace: Loading parcellation 'MelbourneS3' in 'MNI152NLin6Asym' space.
INFO | 20/01/25 13:53:03 | nispace: MelbourneS3 is a subcortex version of the whole-brain parcellation Schaefer400MelbourneS3.
INFO | 20/01/25 13:53:03 | nispace: Removing 400 subcortical parcels and returning Nifti1 object instead of path!
INFO | 20/01/25 13:53:06 | nispace: Input type: list, assuming imaging data.
INFO | 20/01/25 13:53:06 | nispace: Parcellating imaging data.
INFO | 20/01/25 13:53:18 | nispace: Combined across images, 2 parcel(s) had only background intensity and were set to nan ([424, 425]).
INFO | 20/01/25 13:53:18 | nispace: Combined across images, 4 parcels were dropped due to exclusion criteria: min. n = 5 and 10.0% non-background datapoints. ([449, 450, 424, 425]).
WARNING | 20/01/25 13:53:18 | nispace: Parcellated data contains nan values!
Parcellate rest data#
[10]:
from nilearn import maskers
from joblib import Parallel, delayed
parcellater = maskers.NiftiLabelsMasker(
labels_img=parc,
resampling_target="data",
)
dset_rest = Parallel(n_jobs=-1)(
delayed(parcellater.fit_transform)(f)
for f in tqdm(dset_paths.loc["rest",].iloc[:])
)
dset_fc = np.stack([np.corrcoef(arr.T) for arr in dset_rest])
dset_gc = pd.DataFrame(
np.mean(np.arctanh(dset_fc), axis=-1, where=~np.isclose(dset_fc, 1)),
columns=parc_labels,
index=dset_cbf.index
)
#dset_gc.head()
100%|██████████| 63/63 [00:52<00:00, 1.20it/s]
/var/folders/6n/h4150p8d5gz5kbnqv5_406940000gp/T/ipykernel_18554/79596041.py:16: RuntimeWarning: divide by zero encountered in arctanh
np.mean(np.arctanh(dset_fc), axis=-1, where=~np.isclose(dset_fc, 1)),
Fetch reference data#
[32]:
from nispace.datasets import fetch_reference
from nispace.utils.utils import mean_by_set_df
data_pet = fetch_reference("pet", collection="UniqueTracers", parcellation=parcellation,
verbose=False, space=space)
data_pet.index = [l.split("target-")[1].split("_")[0] for l in data_pet.index.get_level_values("map")]
data_pet = data_pet.loc[['NMDA', 'mGluR5',
'GABAa', 'GABAa5',
'5HT1a', '5HT1b', '5HT2a', '5HT4', '5HTT',
'D1', 'D23', 'DAT', 'FDOPA',
'NET',
'A4B2', "M1", 'VAChT',
'VMAT2',
"MOR", "KOR", "CB1",
]]
data_pet
[32]:
| 1_LH_CX_Vis_1 | 2_LH_CX_Vis_2 | 3_LH_CX_Vis_3 | 4_LH_CX_Vis_4 | 5_LH_CX_Vis_5 | 6_LH_CX_Vis_6 | 7_LH_CX_Vis_7 | 8_LH_CX_Vis_8 | 9_LH_CX_Vis_9 | 10_LH_CX_Vis_10 | ... | 441_RH_SC_CAU-DA | 442_RH_SC_CAU-body | 443_RH_SC_CAU-tail | 444_RH_SC_lAMY | 445_RH_SC_mAMY | 446_RH_SC_THA-DP | 447_RH_SC_NAc-shell | 448_RH_SC_NAc-core | 449_RH_SC_pGP | 450_RH_SC_aGP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NMDA | -0.407919 | -0.578907 | -0.082157 | 0.083509 | -0.113249 | -0.393651 | -1.611416 | 0.212830 | 0.062964 | -0.006764 | ... | 1.237660 | 0.888922 | 0.119777 | -0.558601 | -0.952485 | 2.371455 | 1.133501 | 1.224178 | NaN | NaN |
| mGluR5 | -1.130121 | 0.065260 | -1.001370 | -0.271972 | -0.958941 | -1.231485 | -1.356012 | -0.106179 | -1.642800 | -0.858759 | ... | 0.729289 | -1.077105 | -2.498875 | -0.980549 | -1.638254 | -2.032404 | 0.713452 | 1.047602 | NaN | NaN |
| GABAa | 0.805211 | 0.824707 | 1.203976 | 1.264457 | 0.915139 | 0.554488 | 0.227415 | 1.022720 | 1.236833 | 1.280423 | ... | -3.231437 | -3.711237 | -3.889688 | -0.487789 | -1.186902 | -2.584857 | -0.609486 | -2.153542 | NaN | NaN |
| GABAa5 | 0.665263 | 1.639830 | -0.089350 | 0.067058 | -0.758390 | -0.884258 | 0.510409 | 0.085236 | -1.069535 | -0.668361 | ... | -1.466463 | -2.196630 | -2.785367 | 0.148034 | 0.820081 | -1.726285 | 3.753456 | 0.500436 | NaN | NaN |
| 5HT1a | 0.461174 | 1.706476 | 0.029099 | 0.092589 | -0.511766 | -0.088365 | 0.602182 | 0.665945 | -0.693465 | -0.514927 | ... | -2.579780 | -2.671487 | -2.680000 | 1.432610 | 1.659183 | -1.836388 | -1.700532 | -2.188356 | NaN | NaN |
| 5HT1b | -1.272502 | -1.516491 | -0.742401 | -0.575682 | -0.324822 | -0.234034 | -1.914022 | 0.104669 | 0.314445 | -0.297012 | ... | -0.544313 | -1.527975 | -2.580021 | -2.121776 | -1.959093 | -2.329832 | 1.091373 | 0.363674 | NaN | NaN |
| 5HT2a | 0.006237 | 0.292786 | 0.238543 | 0.132588 | 0.206311 | 0.551758 | -0.411539 | 0.777594 | 0.651790 | 0.066243 | ... | -2.659049 | -2.852651 | -3.175906 | -1.636857 | -2.403237 | -2.768682 | -2.010817 | -2.441595 | NaN | NaN |
| 5HT4 | -0.039011 | -0.127525 | -0.100499 | -0.140380 | -0.103626 | -0.202541 | -0.454149 | 0.096307 | -0.335462 | -0.270277 | ... | 4.991557 | 3.734316 | 2.630716 | 0.380015 | 0.235837 | -0.061997 | 3.021399 | 4.810635 | NaN | NaN |
| 5HTT | -0.187468 | 0.169467 | -0.381059 | -0.061315 | -0.439306 | -0.461136 | -0.069336 | -0.282968 | -0.424866 | -0.005101 | ... | 2.084793 | 0.327081 | -0.359263 | 2.074492 | 2.460256 | 1.868303 | 3.949057 | 3.655868 | NaN | NaN |
| D1 | -0.003353 | 0.243864 | -0.178966 | 0.156406 | -0.125171 | -0.555709 | -0.006621 | -0.233153 | -0.325042 | 0.072472 | ... | 4.994437 | 3.777805 | 2.634184 | 0.304812 | -0.011727 | -0.339088 | 3.525863 | 4.719082 | NaN | NaN |
| D23 | -0.198729 | 0.100968 | -0.318275 | -0.200161 | -0.318799 | -0.367771 | -0.212360 | -0.151667 | -0.466975 | -0.395563 | ... | 4.935076 | 3.699561 | 2.507259 | 0.716040 | 0.705880 | 0.332367 | 3.728453 | 4.813808 | NaN | NaN |
| DAT | 0.071070 | 0.354213 | 0.089691 | 0.131745 | 0.171017 | -0.391857 | 0.297250 | -0.302732 | -0.074201 | 0.029208 | ... | 3.818101 | 2.069741 | 0.919793 | 0.904511 | 1.221532 | 0.242120 | 4.775838 | 5.027317 | NaN | NaN |
| FDOPA | 0.115331 | 0.162841 | 0.073582 | -0.064340 | -0.089998 | -0.141794 | -0.103866 | -0.138424 | -0.191887 | -0.281774 | ... | 4.846410 | 3.232830 | 1.799983 | 0.977805 | 0.968372 | 0.096076 | 4.141481 | 4.904483 | NaN | NaN |
| NET | -0.163593 | -0.039630 | -0.334216 | -0.292309 | -0.481404 | -0.611613 | -0.814370 | -0.037162 | -0.597128 | -0.097559 | ... | -1.047941 | -1.307378 | -1.277214 | -0.517207 | -0.456352 | 1.381614 | -0.143300 | -0.614344 | NaN | NaN |
| A4B2 | -0.260814 | -0.477423 | -0.204461 | -0.271543 | -0.278183 | -0.505087 | -0.421770 | -0.448513 | -0.590370 | -0.540533 | ... | 0.575002 | 0.697017 | 0.668675 | -0.594612 | -0.520431 | 3.436977 | 0.421466 | 0.398783 | NaN | NaN |
| M1 | -0.903716 | -0.111074 | -0.616636 | -0.140423 | -0.310640 | -0.562947 | -1.021061 | 0.003075 | -0.607801 | -0.602198 | ... | 3.260115 | 1.321894 | -0.518135 | 0.595445 | -0.070364 | -2.813751 | 3.792695 | 3.971378 | NaN | NaN |
| VAChT | -0.446996 | -0.368667 | -0.420682 | -0.395173 | -0.416532 | -0.506579 | -0.406670 | -0.400049 | -0.488870 | -0.444876 | ... | 4.791719 | 4.095339 | 3.442842 | 0.488155 | 0.635916 | 0.220235 | 3.211327 | 3.913292 | NaN | NaN |
| VMAT2 | -0.085114 | -0.130315 | -0.092539 | -0.104912 | -0.177774 | -0.278983 | -0.154012 | -0.230793 | -0.220649 | -0.173822 | ... | 5.299184 | 3.989932 | 2.597397 | 0.336002 | 0.889680 | -0.104581 | 3.125517 | 4.070830 | NaN | NaN |
| MOR | -0.150789 | -0.198566 | -0.600399 | -0.912555 | -1.352619 | -1.273987 | -0.743391 | -0.491165 | -1.714527 | -1.515526 | ... | 2.366880 | 1.060778 | 0.402003 | 1.660396 | 1.497528 | 0.690918 | 4.251238 | 3.736758 | NaN | NaN |
| KOR | -0.961122 | -0.597462 | -0.578157 | -0.939309 | -0.977459 | -0.592358 | -1.478838 | -0.380224 | -1.324353 | -1.757155 | ... | -1.489651 | -2.343999 | -2.716072 | 1.567268 | 1.130976 | -2.600813 | 1.065448 | -0.067029 | NaN | NaN |
| CB1 | 0.784381 | 0.823254 | 0.486726 | -0.543132 | -0.743175 | 0.423242 | 0.284722 | 0.308839 | 0.016040 | -0.754705 | ... | -0.111155 | -1.603850 | -2.677558 | 1.392643 | 1.021694 | -1.119536 | 1.541331 | 1.220432 | NaN | NaN |
21 rows × 450 columns
Coloc. results#
[33]:
dset_joint = pd.concat(
[dset_cbf, dset_gc],
keys=["cbf", "gc"]
)
#dset_joint
[34]:
from nispace import NiSpace
from nispace.utils.utils import parc_vect_to_vol
nsp_obj = {"wb": {}, "cx": {}, "sc": {}}
plot_vols = {"wb": {}, "cx": {}, "sc": {}}
es_lims = {"wb": {}, "cx": {}, "sc": {}}
n_perm = 10000
for study, drug, placebo in tqdm([("cbf", "risperidone low-dose", "placebo"),
("cbf", "risperidone high-dose", "placebo"),
("gc", "risperidone low-dose", "placebo"),
("gc", "risperidone high-dose", "placebo")]):
dset_drug = dset_joint.loc[(study, drug, slice(None)), :]
dset_placebo = dset_joint.loc[(study, placebo, slice(None)), :]
sessions = [0] * len(dset_drug) + [1] * len(dset_placebo)
subjects = dset_drug.index.get_level_values(-1).tolist() + dset_placebo.index.get_level_values(-1).tolist()
if len(dset_drug) != len(dset_placebo):
ValueError(f"{study}: {drug} vs. {placebo} have different number of subjects")
dset_drug_placebo = pd.concat([dset_drug, dset_placebo], axis=0)
for parc_type, parc_sub, parc_labels_sub in [("wb", parc, parc_labels),
("cx", parc_cx, parc_cx_labels),
("sc", parc_sc, parc_sc_labels)]:
nsp = NiSpace(
x=data_pet[parc_labels_sub],
y=dset_drug_placebo[parc_labels_sub],
z="gm",
parcellation=parc_sub,
parcellation_labels=parc_labels_sub,
parcellation_space="mni152",
n_proc=-1,
verbose=False
).fit()
kwargs = {
"method": "spearman",
"Y_transform": "pairedcohen(a,b)"
}
nsp.transform_y(kwargs["Y_transform"], groups=sessions, subjects=subjects)
nsp.colocalize(**kwargs)
nsp.permute("groups", **kwargs, n_perm=n_perm, seed=42)
#nsp.plot(**kwargs, title=f"{drug} - {placebo}", permute_what="groups")
# save nsp object
nsp_obj[parc_type][(study, drug)] = nsp
# get es vector
es = nsp.get_y(kwargs["Y_transform"]).squeeze()
# save volume
plot_vols[parc_type][(study, drug)] = parc_vect_to_vol(es, parc_sub)
# save min/max
es_lims[parc_type][(study, drug)] = (es.min(), es.max())
INFO | 20/01/25 14:01:18 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
/Applications/miniforge3/envs/nsp309/lib/python3.9/site-packages/joblib/externals/loky/process_executor.py:752: UserWarning: A worker stopped while some jobs were given to the executor. This can be caused by a too short worker timeout or by a memory leak.
warnings.warn(
INFO | 20/01/25 14:01:55 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:02:07 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:02:17 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:02:27 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:02:38 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:02:48 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:02:59 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:03:11 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:03:21 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:03:32 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
INFO | 20/01/25 14:03:44 | nispace: Loading MNI152NLin2009cAsym 'gmprob' template in '1mm' resolution.
100%|██████████| 4/4 [02:35<00:00, 38.99s/it]
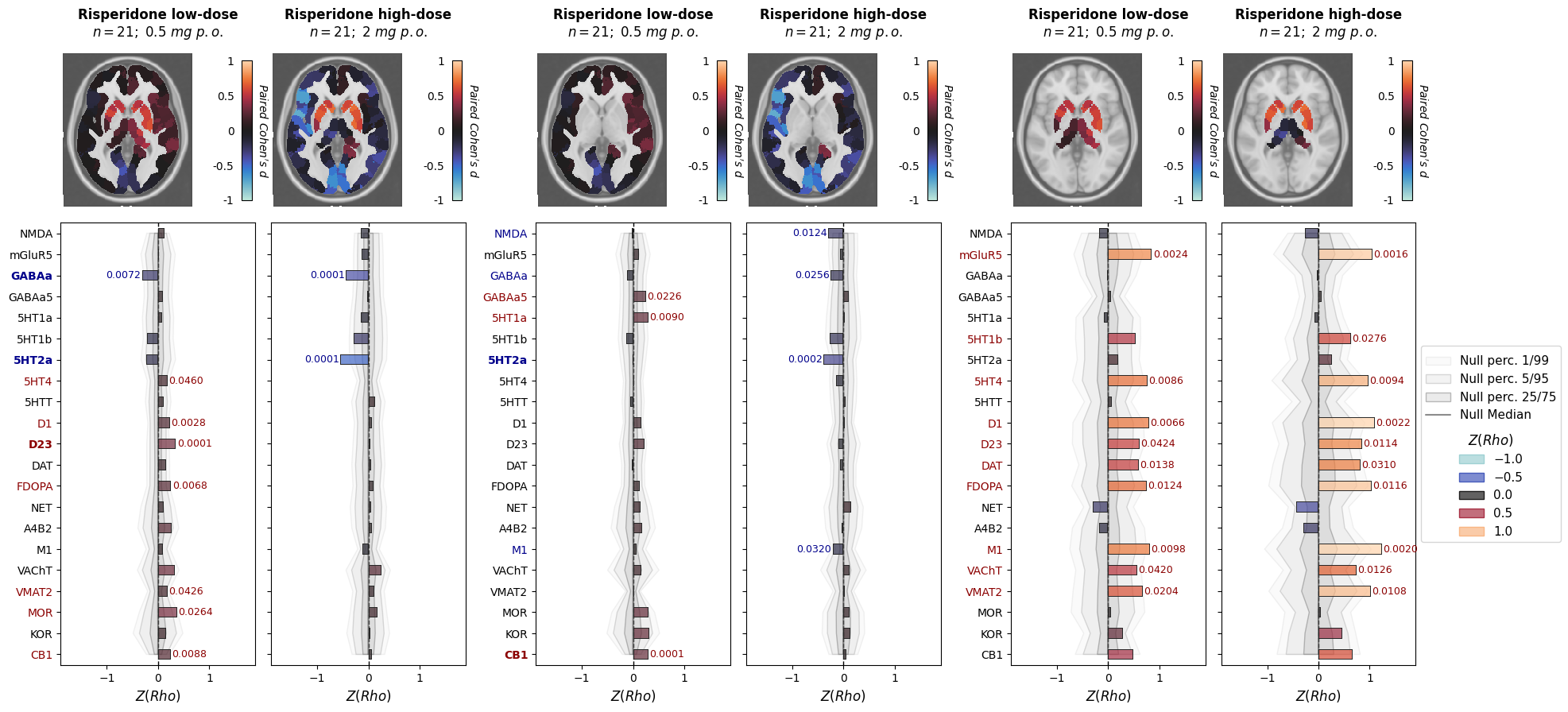
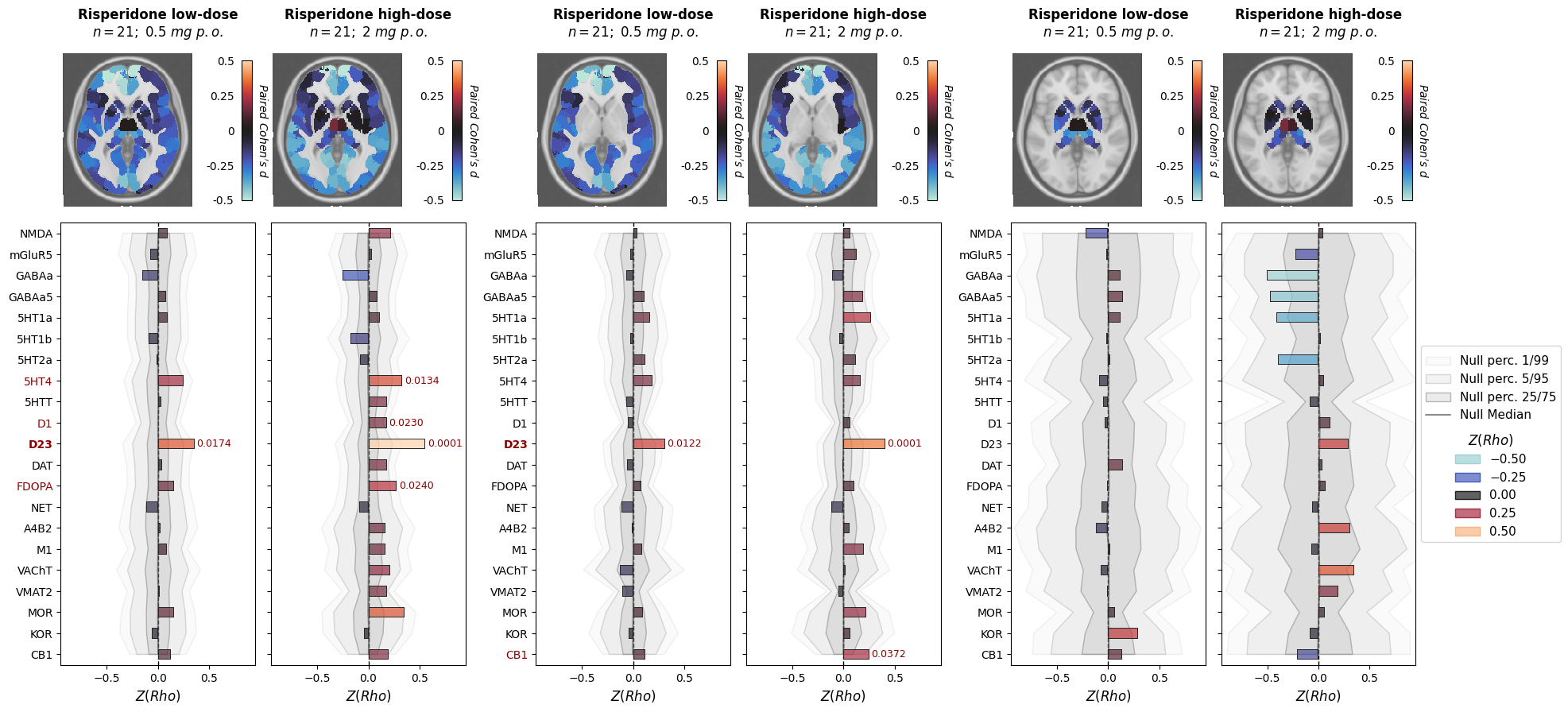
[36]:
from nilearn.plotting import plot_stat_map
from nispace.datasets import fetch_template
drug_info = {
"risperidone low-dose": f"n={dset_joint.loc[('cbf', 'risperidone low-dose', slice(None)), :].shape[0]}; 0.5 mg p.o.",
"risperidone high-dose": f"n={dset_joint.loc[('cbf', 'risperidone high-dose', slice(None)), :].shape[0]}; 2 mg p.o."
}
for metric, x_lims, rho_lims, es_absmax in [("cbf", (-1.9, 1.9), (-1.1, 1.1), 1),
("gc", (-0.95, 0.95), (-0.55, 0.55), 0.5)]:
#es_absmax = max(abs(np.concatenate([es_lims[parc_type][(metric, drug)] for drug in drug_info])))
fig, axes = plt.subplots(2, 6+2, figsize=(22, 10), sharex="row",
gridspec_kw={"height_ratios": (0.35, 1),
"width_ratios": (1,1, 0.2, 1,1, 0.2, 1,1),
"hspace": 0.05,
"wspace": 0.1})
for c, parc_type in [(0, "wb"),
(3, "cx"),
(6, "sc")]:
if c < 6:
axes[0, c+2].set_axis_off()
axes[1, c+2].set_axis_off()
for cc, drug in enumerate(drug_info):
nsp = nsp_obj[parc_type][(metric, drug)]
vol = plot_vols[parc_type][(metric, drug)]
# title
ax = axes[0, c+cc]
ax.set_title(
drug.capitalize() + "\n$" + drug_info[drug].replace(" ", "\ ") + "$",
weight="semibold",
pad=15,
size=12
)
# brain
plot = plot_stat_map(
vol,
bg_img=fetch_template("MNI152NLin6Asym"),
black_bg=False,
display_mode="z",
cut_coords=[0],
axes=ax,
cmap="icefire", vmax=es_absmax,
colorbar=True,
annotate=False
)
plot._colorbar_ax.set_ylabel("$Paired\ Cohen's\ d$", rotation=-90, va="bottom")
# bars
ax = axes[1, c+cc]
nsp.plot(
**kwargs, ax=ax, fig=fig, permute_what="groups", verbose=False, show=False, title=None,
plot_kwargs={
"limits": {
"x": x_lims,
"color": rho_lims
},
"legend": {
"plot": True if ax.get_subplotspec().is_last_col() else False,
"kwargs": {"title": "$Z(Rho)$"}
}
},
nullplot_kwargs={
"legend": {
"plot": True if ax.get_subplotspec().is_last_col() else False,
"kwargs": {"title": "$Null distribution$"}
}
}
)
ax.set_xlabel("$Z(Rho)$", size=12)
# p values
p_values = nsp.get_p_values(permute_what="groups", **kwargs).loc["mean"]
coloc_values = nsp.get_colocalizations(**kwargs).mean()
for p_y_pos, (lab, p_val, coloc_val) in enumerate(zip(axes[1, c].get_yticklabels(), p_values, coloc_values)):
if p_val < 0.05:
lab.set_color("darkred" if coloc_val > 0 else "darkblue")
if p_val <= 0.001:
lab.set_weight("bold")
ax.annotate(
f"{p_val:.04f}",
xy=(coloc_val + (0.02 if coloc_val > 0 else -0.02), p_y_pos),
size=9,
color="darkred" if coloc_val > 0 else "darkblue",
ha="left" if coloc_val > 0 else "right",
va='center'
)
if cc == 1:
ax.set_yticklabels([])
# save
fig.savefig(f"drug_challenge_plot_{metric}.pdf", bbox_inches="tight", dpi=300)
plt.show()
INFO | 20/01/25 14:06:32 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
Downloading /Users/llotter/nispace-data/template/MNI152NLin6Asym/map/T1w/tpl-MNI152NLin6Asym_desc-T1w_res-1mm.nii.gz.
/Applications/miniforge3/envs/nsp309/lib/python3.9/site-packages/nilearn/plotting/img_plotting.py:1317: UserWarning: Non-finite values detected. These values will be replaced with zeros.
safe_get_data(stat_map_img, ensure_finite=True),
INFO | 20/01/25 14:06:38 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
/Applications/miniforge3/envs/nsp309/lib/python3.9/site-packages/nilearn/plotting/img_plotting.py:1317: UserWarning: Non-finite values detected. These values will be replaced with zeros.
safe_get_data(stat_map_img, ensure_finite=True),
INFO | 20/01/25 14:06:40 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
INFO | 20/01/25 14:06:43 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
INFO | 20/01/25 14:06:45 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
/Applications/miniforge3/envs/nsp309/lib/python3.9/site-packages/nilearn/plotting/img_plotting.py:1317: UserWarning: Non-finite values detected. These values will be replaced with zeros.
safe_get_data(stat_map_img, ensure_finite=True),
INFO | 20/01/25 14:06:47 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
/Applications/miniforge3/envs/nsp309/lib/python3.9/site-packages/nilearn/plotting/img_plotting.py:1317: UserWarning: Non-finite values detected. These values will be replaced with zeros.
safe_get_data(stat_map_img, ensure_finite=True),
INFO | 20/01/25 14:06:51 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
INFO | 20/01/25 14:06:54 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
INFO | 20/01/25 14:06:56 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
INFO | 20/01/25 14:06:59 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
INFO | 20/01/25 14:07:02 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
INFO | 20/01/25 14:07:04 | nispace: Loading MNI152NLin6Asym 'T1w' template in '1mm' resolution.
[ ]: