Null models and permutation testing
We touched on null models briefly in Notebook 1 (conceptual background) and Notebook 2 (where we called permute("maps") without much explanation). This notebook explains what’s happening under the hood and when to use which approach.
There are two fundamentally different situations that call for different null models:
You have a single group-level map (e.g., the pain NeuroQuery map, a published effect size): permute the reference maps.
You have individual subject data and a group design (e.g., the anorexia nervosa dataset): permute the group labels.
For X-Set Enrichment Analysis, there’s a third type — we’ll cover that in Notebook 10.
[2]:
import tqdm.notebook
tqdm.notebook.tqdm = tqdm.tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
[3]:
from nispace.datasets import fetch_reference, fetch_example
from nispace.io import load_img
from nispace.api import NiSpace
# set up with the pain map
pet_maps = fetch_reference("pet", parcellation="Yan200",
collection="UniqueTracers", print_references=False)
pain_map = load_img("neuroquery/pain.nii.gz")
nsp = NiSpace(x=pet_maps, y=pain_map, y_labels="Pain",
parcellation="Yan200", seed=42, n_proc=4)
nsp.fit()
nsp.colocalize("spearman")
INFO | 20/07/26 18:20:48 | nispace.datasets: Loading pet maps.
INFO | 20/07/26 18:20:48 | nispace.datasets: Loading integrated collection 'UniqueTracers' for dataset 'pet'.
INFO | 20/07/26 18:20:48 | nispace.datasets: Filtering maps by collection.
INFO | 20/07/26 18:20:48 | nispace.datasets: Loading data parcellated with 'Yan200'
INFO | 20/07/26 18:20:48 | nispace.api: *** NiSpace.fit() - Data extraction and preparation. ***
INFO | 20/07/26 18:20:48 | nispace.core.parcellation: Building cortex Parcellation for 'Yan200' from library. DOI: 10.1016/j.neuroimage.2023.120010
INFO | 20/07/26 18:20:48 | nispace.core.parcellation: Available spaces: MNI152NLin2009cAsym, MNI152NLin6Asym, fsLR, fsaverage
INFO | 20/07/26 18:20:49 | nispace.core.parcellation: Parcellation 'Yan200': validation passed.
INFO | 20/07/26 18:20:49 | nispace.core.parcellation: Lazy-loading parcellation image for space 'MNI152NLin2009cAsym'.
INFO | 20/07/26 18:20:49 | nispace.core.parcellation: Parcellation 'Yan200': active space set to 'MNI152NLin2009cAsym'.
INFO | 20/07/26 18:20:49 | nispace.api: Checking input data for 'x' (should be, e.g., PET data):
INFO | 20/07/26 18:20:49 | nispace.io: Input type: DataFrame, assuming parcellated data with shape (n_files/subjects/etc, n_parcels).
WARNING | 20/07/26 18:20:49 | nispace.io: Parcellated data contains nan values!
INFO | 20/07/26 18:20:49 | nispace.api: Got 'x' data for 29 x 200 parcels.
INFO | 20/07/26 18:20:49 | nispace.api: Checking input data for 'y' (should be, e.g., subject data):
INFO | 20/07/26 18:20:49 | nispace.io: Input type: list, assuming imaging data.
INFO | 20/07/26 18:20:49 | nispace.io: Background (bg) handling: background_value='auto'; reporting bg-only parcels: False
INFO | 20/07/26 18:20:49 | nispace.io: Parcellating imaging data.
Parcellating (4 proc): 100%|█████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 127.18it/s]
INFO | 20/07/26 18:20:53 | nispace.api: Got 'y' data for 1 x 200 parcels.
INFO | 20/07/26 18:20:53 | nispace.api: Z-standardizing 'X' data.
INFO | 20/07/26 18:20:53 | nispace.api: *** NiSpace.colocalize() - Estimating X & Y colocalizations. ***
INFO | 20/07/26 18:20:53 | nispace.api: Running 'spearman' colocalization.
INFO | 20/07/26 18:20:53 | nispace.api: Pre-ranking X and Y data.
Colocalizing (spearman, 4 proc): 100%|██████████████████████████████████████████████████| 1/1 [00:00<00:00, 1949.03it/s]
[3]:
<nispace.api.NiSpace at 0x1696afeb0>
Part 1: Surrogate map null models
When you call permute("maps"), NiSpace generates spatially-constrained random versions of the reference maps and recomputes the correlation with your input map for each permutation. The empirical distribution of these null correlations becomes the null distribution.
The null method is auto-selected based on the parcellation type — you can customize this, but usually should not need to.
Cortical-only parcellations: Moran spectral randomization (
"moran") is chosen automaticallyCombined (cx+sc) parcellations: Split Moran spectral randomization (
("moran", "moran")) is chosen automatically — cortex and subcortex are treated independently
Several methods are available (more are continuously added):
Method |
Key idea |
When selected |
|---|---|---|
|
Moran spectral randomization: Randomize spectral coefficients of the spatial covariance |
Auto-default for cortical-only parcellations |
|
Split Moran: run independently on cortex and subcortex |
Auto-default for combined (cx+sc) parcellations |
|
Fractional transition spin: for each rotation, the null map value at parcel i is a weighted average over all parcels that received its vertices. |
Cortical-only parcellations; explicit choice |
|
Vertex-level rotation + modal parcel assignment |
Alternative spin; explicit choice |
|
Original nearest-centroid spin (Alexander-Bloch et al. 2018) |
Alternative spin; explicit choice |
|
As in the Alexander-Bloch method, but exact reassignments instead of nearest-centroid |
Alternative spin; explicit choice |
|
As in the Alexander-Bloch method, but hungarian matching instead of nearest-centroid |
Alternative spin; explicit choice |
|
Auto-regressive model to match data-distance relationship |
Explicit choice; any parcellation |
|
Match the spatial variogram of the original map |
Explicit choice; any parcellation |
Moran Spectral Randomization (moran)
Moran spectral randomization decomposes the spatial covariance structure of the parcellation into eigenvectors (Moran eigenvectors), then randomizes the spectral coefficients while preserving the overall structure. The result is a null map with the same degree of spatial autocorrelation, but with the specific spatial pattern scrambled.
Two key properties:
Works with any parcellation geometry — subcortical structures, volumetric atlases, anything.
No precomputed matrix needed — eigenvectors are derived on the fly from the parcellation distance matrix.
Moran is auto-selected for cortical-only parcellations like Yan200:
[4]:
# moran is auto-selected for all parcellations, so null_method can be omitted
nsp.permute("maps", n_perm=1000, p_tails="upper")
p_moran = nsp.get_p_values()
print("Moran spectral — 5 lowest p-values:")
p_moran.T.sort_values(by="Pain").head(5)
INFO | 20/07/26 18:20:56 | nispace.api: *** NiSpace.permute() - Estimate exact non-parametric p values. ***
INFO | 20/07/26 18:20:56 | nispace.api: Permutation of: X maps.
INFO | 20/07/26 18:20:56 | nispace.api: Using default null method 'moran' (parcellation null space: 'fsLR').
INFO | 20/07/26 18:20:56 | nispace.core.parcellation: Lazy-loading parcellation image for space 'fsLR'.
INFO | 20/07/26 18:20:56 | nispace.api: Loading observed colocalizations (method = 'spearman').
INFO | 20/07/26 18:20:56 | nispace.core.permute: Generating null maps (n = 1000, null_method = 'moran').
INFO | 20/07/26 18:20:56 | nispace.nulls: Null map generation: Assuming n = 29 data vector(s) for n = 200 parcels.
INFO | 20/07/26 18:20:56 | nispace.nulls: Using provided distance matrix/matrices.
Moran null maps (4 proc): 100%|█████████████████████████████████████████████████████████| 29/29 [00:00<00:00, 67.42it/s]
INFO | 20/07/26 18:20:58 | nispace.nulls: Null data generation finished.
INFO | 20/07/26 18:20:58 | nispace.core.permute: Z-standardizing null maps.
Processing null arrays (4 proc): 100%|█████████████████████████████████████████████| 1000/1000 [00:01<00:00, 936.32it/s]
Null colocalizations (spearman, 4 proc): 100%|████████████████████████████████████| 1000/1000 [00:00<00:00, 7854.84it/s]
INFO | 20/07/26 18:21:00 | nispace.core.permute: Calculating exact p-values (tails = {'rho': 'upper'}).
Moran spectral — 5 lowest p-values:
[4]:
| Pain | ||
|---|---|---|
| set | map | |
| Noradrenaline/Acetylcholine | target-VAChT_tracer-feobv_n-18_dx-hc_pub-aghourian2017 | 0.073 |
| Opioids/Endocannabinoids | target-KOR_tracer-ly2795050_n-28_dx-hc_pub-vijay2018 | 0.103 |
| Histamine | target-H3_tracer-gsk189254_n-8_dx-hc_pub-gallezot2017 | 0.164 |
| Glutamate | target-mGluR5_tracer-abp688_n-73_dx-hc_pub-smart2019 | 0.172 |
| Noradrenaline/Acetylcholine | target-NET_tracer-mrb_n-10_dx-hc_pub-hesse2017 | 0.255 |
The spin test (cornblath)
For cortical-only parcellations with a surface space (fsLR, fsaverage), an alternative is the spin test. A commonly used spin method is "cornblath" (Cornblath et al., 2020), as recommended by Markello & Misic (2021).
The spin test works by projecting the cortical parcellation onto a sphere and applying random rotations. This preserves the spatial topology of the original map while breaking any specific spatial relationship with the input map.
We implement the method via a fractional transition matrix: for each random rotation, it records what fraction of each parcel’s surface vertices land in each other parcel. The null map value for parcel i is then a weighted average over all parcels that received its vertices. This implementation has the big advantage that the transition matrices can be stored and re-applied. For all included cortical parcellations, NiSpace automatically downloads 10,000 of these matrices, reducing
computation time to a few seconds. The alias "spin" maps to "cornblath" — they are identical.
To use the spin test, pass maps_method="cornblath" explicitly:
[5]:
nsp.permute("maps", maps_method="cornblath", n_perm=1000, p_tails="upper")
p_spin = nsp.get_p_values()
print("Cornblath spin — 5 lowest p-values:")
p_spin.T.sort_values(by="Pain").head(5)
INFO | 20/07/26 18:21:00 | nispace.core.permute: Found existing null maps.
WARNING | 20/07/26 18:21:00 | nispace.core.permute: Null method changed. Will re-generate.
INFO | 20/07/26 18:21:00 | nispace.core.permute: Generating null maps (n = 1000, null_method = 'cornblath').
INFO | 20/07/26 18:21:00 | nispace.nulls: Null map generation: Assuming n = 29 data vector(s) for n = 200 parcels.
INFO | 20/07/26 18:21:00 | nispace.nulls: Using provided precomputed Cornblath transition matrix.
Cornblath null maps: 100%|██████████████████████████████████████████████████████████████| 29/29 [00:01<00:00, 14.51it/s]
INFO | 20/07/26 18:21:02 | nispace.nulls: Null data generation finished.
INFO | 20/07/26 18:21:02 | nispace.core.permute: Z-standardizing null maps.
Processing null arrays (4 proc): 100%|████████████████████████████████████████████| 1000/1000 [00:00<00:00, 6252.26it/s]
Null colocalizations (spearman, 4 proc): 100%|███████████████████████████████████| 1000/1000 [00:00<00:00, 12429.00it/s]
INFO | 20/07/26 18:21:04 | nispace.core.permute: Calculating exact p-values (tails = {'rho': 'upper'}).
Cornblath spin — 5 lowest p-values:
[5]:
| Pain | ||
|---|---|---|
| set | map | |
| Noradrenaline/Acetylcholine | target-VAChT_tracer-feobv_n-18_dx-hc_pub-aghourian2017 | 0.039 |
| Opioids/Endocannabinoids | target-KOR_tracer-ly2795050_n-28_dx-hc_pub-vijay2018 | 0.058 |
| Noradrenaline/Acetylcholine | target-NET_tracer-mrb_n-10_dx-hc_pub-hesse2017 | 0.114 |
| Histamine | target-H3_tracer-gsk189254_n-8_dx-hc_pub-gallezot2017 | 0.124 |
| Glutamate | target-mGluR5_tracer-abp688_n-73_dx-hc_pub-smart2019 | 0.257 |
[6]:
# compare spin and Moran side by side
comparison = pd.DataFrame({
"rho": nsp.get_colocalizations().T["Pain"],
"p_spin": p_spin.T["Pain"],
"p_moran": p_moran.T["Pain"],
}).sort_values("p_spin")
comparison.head(10)
[6]:
| rho | p_spin | p_moran | ||
|---|---|---|---|---|
| set | map | |||
| Noradrenaline/Acetylcholine | target-VAChT_tracer-feobv_n-18_dx-hc_pub-aghourian2017 | 0.422783 | 0.039 | 0.073 |
| Opioids/Endocannabinoids | target-KOR_tracer-ly2795050_n-28_dx-hc_pub-vijay2018 | 0.335397 | 0.058 | 0.103 |
| Noradrenaline/Acetylcholine | target-NET_tracer-mrb_n-10_dx-hc_pub-hesse2017 | 0.288889 | 0.114 | 0.255 |
| Histamine | target-H3_tracer-gsk189254_n-8_dx-hc_pub-gallezot2017 | 0.273213 | 0.124 | 0.164 |
| Glutamate | target-mGluR5_tracer-abp688_n-73_dx-hc_pub-smart2019 | 0.180214 | 0.257 | 0.172 |
| Opioids/Endocannabinoids | target-MOR_tracer-carfentanil_n-204_dx-hc_pub-kantonen2020 | 0.171576 | 0.258 | 0.259 |
| Serotonin | target-5HTT_tracer-dasb_n-18_dx-hc_pub-savli2012 | 0.145715 | 0.272 | 0.294 |
| Dopamine | target-DAT_tracer-fpcit_n-174_dx-hc_pub-dukart2018 | 0.097589 | 0.336 | 0.332 |
| GABA | target-GABAa5_tracer-ro154513_n-10_dx-hc_pub-lukow2022 | 0.107938 | 0.354 | 0.347 |
| Opioids/Endocannabinoids | target-CB1_tracer-omar_n-77_dx-hc_pub-normandin2015 | 0.101408 | 0.380 | 0.358 |
Combined parcellations: split Moran on cortex and subcortex
For combined (cortex + subcortex) parcellations, the spin test cannot cover the whole brain — subcortical structures have no spherical surface projection. NiSpace’s default for combined parcellations is therefore split Moran spectral randomization (``(“moran”, “moran”)``) — running independently on the cortical and subcortical components using their respective distance matrices.
Why split? Many reference maps and input maps have a cortical-subcortical gradient. If nulls were generated on the full combined distance matrix (whole-brain Moran), this gradient would be scrambled in the nulls — inflating the effective variance and making the test more conservative. Generating nulls separately for cortex and subcortex preserves the value distributions within each compartment, retaining the overall gradient and producing better-calibrated tests.
Are you testing spatial correlations beyond a cortex-subcortex gradient, or is the alignment between these compartments itself part of your hypothesis? If cortex-subcortex alignment is part of the signal you want to test, use whole-brain
"moran"instead.
|
Notes |
|---|---|
|
Auto-default for combined parcellations; split Moran on cx and sc dist_mats |
|
Whole-brain Moran on full combined dist_mat; explicit choice |
|
Split: spin for cortex, Moran for subcortex; explicit choice |
|
Alternative spin for cortex |
|
Legacy spin variant |
|
Variogram for subcortex |
|
BrainSmash variogram on full combined dist_mat |
|
Burt 2018 method on full combined dist_mat |
The subcortex position of split methods only accepts non-spin options ("moran", "burt2020", "burt2018").
[7]:
from nispace.datasets import fetch_reference as _fr
# load PET maps for combined parcellation
pet_combined = _fr("pet", parcellation="Yan200+TianS1",
collection="UniqueTracers", print_references=False)
nsp_combined = NiSpace(x=pet_combined, y=pain_map, y_labels="Pain",
parcellation="Yan200+TianS1", seed=42, n_proc=4)
nsp_combined.fit()
nsp_combined.colocalize("spearman")
# auto-selects ("moran", "moran") — split Moran on cortex and subcortex separately
nsp_combined.permute("maps", n_perm=500, p_tails="upper")
p_combined = nsp_combined.get_p_values()
print("Combined parcellation (moran+moran, default) — 5 lowest p-values:")
p_combined.T.sort_values(by="Pain").head(5)
INFO | 20/07/26 18:21:04 | nispace.datasets: Loading pet maps.
INFO | 20/07/26 18:21:04 | nispace.datasets: Loading integrated collection 'UniqueTracers' for dataset 'pet'.
INFO | 20/07/26 18:21:04 | nispace.datasets: Filtering maps by collection.
INFO | 20/07/26 18:21:04 | nispace.datasets: Loading and inner-merging data parcellated with 'Yan200' and 'TianS1'
INFO | 20/07/26 18:21:04 | nispace.core.parcellation: Building combined Parcellation 'Yan200+TianS1' from library.
INFO | 20/07/26 18:21:04 | nispace.core.parcellation: Common MNI space(s) for combined: ['MNI152NLin2009cAsym', 'MNI152NLin6Asym'].
INFO | 20/07/26 18:21:04 | nispace.core.parcellation: Merging 'Yan200' and 'TianS1' for space 'MNI152NLin2009cAsym'.
INFO | 20/07/26 18:21:04 | nispace.core.parcellation: Merging 'Yan200' and 'TianS1' for space 'MNI152NLin6Asym'.
INFO | 20/07/26 18:21:04 | nispace.core.parcellation: Fetching cx surface data for 'Yan200' in 'fsLR' (for spin tests).
INFO | 20/07/26 18:21:04 | nispace.core.parcellation: Fetching cx surface data for 'Yan200' in 'fsaverage' (for spin tests).
INFO | 20/07/26 18:21:05 | nispace.core.parcellation: Combined parcellation 'Yan200+TianS1' ready. MNI space(s): ['MNI152NLin2009cAsym', 'MNI152NLin6Asym']. Cx surface space(s) for spins: ['fsLR', 'fsaverage'].
INFO | 20/07/26 18:21:05 | nispace.core.parcellation: Parcellation 'Yan200+TianS1': validation passed.
INFO | 20/07/26 18:21:05 | nispace.core.parcellation: Parcellation 'Yan200+TianS1': active space set to 'MNI152NLin2009cAsym'.
INFO | 20/07/26 18:21:05 | nispace.core.parcellation: Combined parcellation: cx-LH parcels = 100, cx-RH parcels = 100.
INFO | 20/07/26 18:21:05 | nispace.io: Input type: DataFrame, assuming parcellated data with shape (n_files/subjects/etc, n_parcels).
WARNING | 20/07/26 18:21:05 | nispace.io: Parcellated data contains nan values!
INFO | 20/07/26 18:21:05 | nispace.io: Input type: list, assuming imaging data.
INFO | 20/07/26 18:21:05 | nispace.io: Background (bg) handling: background_value='auto'; reporting bg-only parcels: False
INFO | 20/07/26 18:21:05 | nispace.io: Parcellating imaging data.
Parcellating (4 proc): 100%|████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1811.79it/s]
Colocalizing (spearman, 4 proc): 100%|██████████████████████████████████████████████████| 1/1 [00:00<00:00, 1957.21it/s]
INFO | 20/07/26 18:21:06 | nispace.core.permute: Generating null maps (n = 500, null_method = 'moran+moran').
INFO | 20/07/26 18:21:06 | nispace.core.parcellation: Lazy-loading sc dist mat for 'TianS1' (space 'MNI152NLin6Asym').
INFO | 20/07/26 18:21:06 | nispace.core.parcellation: Lazy-loading cx dist mat for 'Yan200' (space 'fsLR').
INFO | 20/07/26 18:21:06 | nispace.nulls: Split null method: cx='moran' (200 parcels), sc='moran' (16 parcels).
INFO | 20/07/26 18:21:06 | nispace.nulls: Null map generation: Assuming n = 29 data vector(s) for n = 200 parcels.
INFO | 20/07/26 18:21:06 | nispace.nulls: Using provided distance matrix/matrices.
Moran null maps (4 proc): 100%|████████████████████████████████████████████████████████| 29/29 [00:00<00:00, 162.44it/s]
INFO | 20/07/26 18:21:06 | nispace.nulls: Null data generation finished.
INFO | 20/07/26 18:21:06 | nispace.nulls: Null map generation: Assuming n = 29 data vector(s) for n = 16 parcels.
INFO | 20/07/26 18:21:06 | nispace.nulls: Using provided distance matrix/matrices.
Moran null maps (4 proc): 100%|████████████████████████████████████████████████████████| 29/29 [00:00<00:00, 357.83it/s]
INFO | 20/07/26 18:21:07 | nispace.nulls: Null data generation finished.
INFO | 20/07/26 18:21:07 | nispace.core.permute: Z-standardizing null maps.
Processing null arrays (4 proc): 100%|██████████████████████████████████████████████| 500/500 [00:00<00:00, 4494.66it/s]
Null colocalizations (spearman, 4 proc): 100%|██████████████████████████████████████| 500/500 [00:00<00:00, 8798.96it/s]
INFO | 20/07/26 18:21:07 | nispace.core.permute: Calculating exact p-values (tails = {'rho': 'upper'}).
Combined parcellation (moran+moran, default) — 5 lowest p-values:
[7]:
| Pain | ||
|---|---|---|
| set | map | |
| Noradrenaline/Acetylcholine | target-VAChT_tracer-feobv_n-18_dx-hc_pub-aghourian2017 | 0.058 |
| Opioids/Endocannabinoids | target-KOR_tracer-ly2795050_n-28_dx-hc_pub-vijay2018 | 0.090 |
| Histamine | target-H3_tracer-gsk189254_n-8_dx-hc_pub-gallezot2017 | 0.192 |
| Glutamate | target-mGluR5_tracer-abp688_n-73_dx-hc_pub-smart2019 | 0.220 |
| Noradrenaline/Acetylcholine | target-NET_tracer-mrb_n-10_dx-hc_pub-hesse2017 | 0.248 |
Part 2: Group permutation
When you have individual subject data and a group comparison design, permuting the reference maps isn’t quite right — you should permute the group labels instead. The logic is:
If the colocalization between the patient effect size map and a reference map is real, then randomly reassigning subjects to groups should produce smaller effect sizes, and hence smaller colocalizations.
This is implemented with permute("groups"). We use the anorexia nervosa example dataset below.
Note: This dataset is simulated and not intended for scientific use.
[8]:
# set up with the anorexia nervosa dataset
an_data = fetch_example("anorexianervosa", parcellation="Yan200")
groups = an_data.index.str.extract(r'(AN|HC)$')[0].values
nsp_groups = NiSpace(x=pet_maps, y=an_data, parcellation="Yan200",
seed=42, n_proc=4)
nsp_groups.fit()
# compute effect sizes first
nsp_groups.transform_y(transform="hedges(a,b)", groups=groups)
nsp_groups.colocalize("spearman")
# group permutation: randomly shuffle the AN/HC labels and recompute
nsp_groups.permute(
"groups",
groups=groups,
n_perm=1000, # increase to >=10000 for final analyses
p_tails="two" # two-tailed: we don't have a directional hypothesis here
)
p_groups = nsp_groups.get_p_values()
y_label = p_groups.index[0]
print(f"Group permutation ({y_label}) — 5 lowest p-values:")
p_groups.T.sort_values(by=y_label).head(5)
INFO | 20/07/26 18:21:07 | nispace.datasets: Loading example dataset: 'anorexianervosa', parcellated with: Yan200.
INFO | 20/07/26 18:21:07 | nispace.core.parcellation: Building cortex Parcellation for 'Yan200' from library. DOI: 10.1016/j.neuroimage.2023.120010
INFO | 20/07/26 18:21:07 | nispace.core.parcellation: Available spaces: MNI152NLin2009cAsym, MNI152NLin6Asym, fsLR, fsaverage
INFO | 20/07/26 18:21:08 | nispace.core.parcellation: Parcellation 'Yan200': validation passed.
INFO | 20/07/26 18:21:08 | nispace.io: Input type: DataFrame, assuming parcellated data with shape (n_files/subjects/etc, n_parcels).
WARNING | 20/07/26 18:21:08 | nispace.io: Parcellated data contains nan values!
INFO | 20/07/26 18:21:08 | nispace.io: Input type: DataFrame, assuming parcellated data with shape (n_files/subjects/etc, n_parcels).
Colocalizing (spearman, 4 proc): 100%|██████████████████████████████████████████████████| 1/1 [00:00<00:00, 1692.62it/s]
INFO | 20/07/26 18:21:08 | nispace.core.parcellation: Lazy-loading parcellation image for space 'fsLR'.
Permuting groups (4 proc): 100%|████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 885621.62it/s]
Null transformations (spearman, 4 proc): 100%|████████████████████████████████████| 1000/1000 [00:00<00:00, 4227.69it/s]
Processing null arrays (4 proc): 100%|████████████████████████████████████████████| 1000/1000 [00:00<00:00, 4165.09it/s]
Null colocalizations (spearman, 4 proc): 100%|███████████████████████████████████| 1000/1000 [00:00<00:00, 13900.11it/s]
INFO | 20/07/26 18:21:09 | nispace.core.permute: Calculating exact p-values (tails = {'rho': 'two'}).
Group permutation (hedges) — 5 lowest p-values:
[8]:
| hedges | ||
|---|---|---|
| set | map | |
| Serotonin | target-5HT1a_tracer-way100635_n-35_dx-hc_pub-savli2012 | 0.001 |
| Dopamine | target-D23_tracer-flb457_n-55_dx-hc_pub-sandiego2015 | 0.001 |
| target-FDOPA_tracer-fluorodopa_n-12_dx-hc_pub-garciagomez2018 | 0.002 | |
| GABA | target-GABAa5_tracer-ro154513_n-10_dx-hc_pub-lukow2022 | 0.004 |
| Serotonin | target-5HTT_tracer-dasb_n-18_dx-hc_pub-savli2012 | 0.004 |
Which null model should I use?
A practical guide:
Situation |
Recommended null model |
|---|---|
Single cortical map (published effect size, meta-analytic map) |
|
Single map with combined (cx+sc) parcellation |
|
Single map with volumetric-only parcellation |
|
Individual subject data with group comparison |
|
XSEA (set enrichment) |
|
Group permutation is more computationally expensive (the effect size must be recomputed for each permutation) but is more appropriate when you have individual-level data.
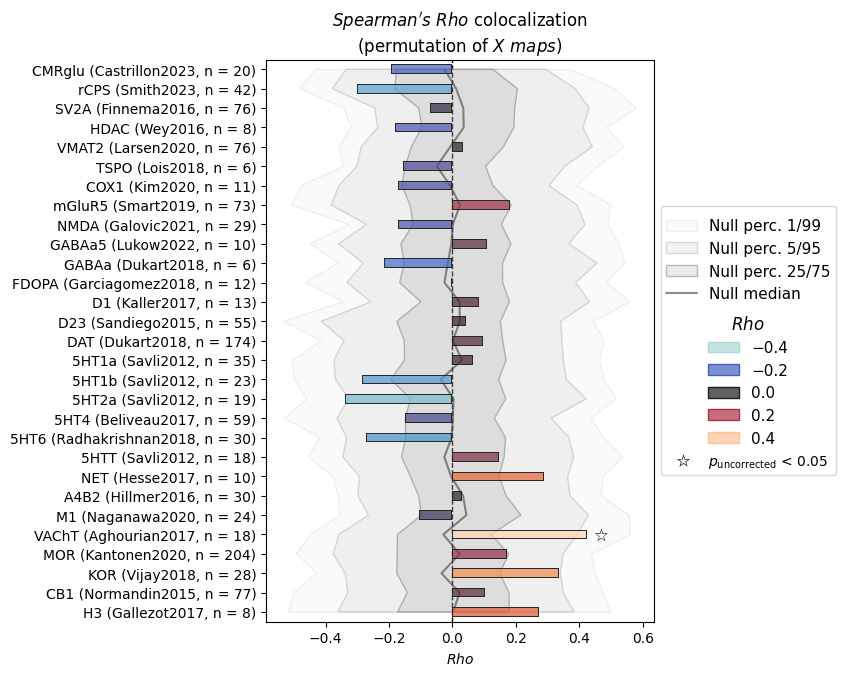
Part 3: Visualizing the null distribution
After calling permute(), the null distribution is stored internally and used when you call nsp.plot(). The grey shading in the plot represents the null distribution percentiles.
[9]:
# correct p values
nsp.correct_p()
# plot with null distribution shading
nsp.plot()
INFO | 20/07/26 18:21:10 | nispace.plotting: Significance annotation: 1/29 p_uncorrected < 0.05, 0/29 p_meffgalwey < 0.05
[9]:
(<Figure size 500x730 with 1 Axes>,
<Axes: title={'center': "$Spearman's\\ Rho$ colocalization\n(permutation of $X\\ maps$)"}, xlabel='$Rho$'>,
<seaborn._core.plot.Plotter at 0x347dc9f70>)
Summary
permute("maps")without specifyingnull_method— auto-selects"moran"for cortical-only,("moran", "moran")for combined (cx+sc) parcellationspermute("maps", null_method="moran")— Moran spectral randomization; for combined parcellations, treats cx+sc as one region (whole-brain); explicit overridepermute("maps", null_method=("moran", "moran"))— split Moran; auto-default for combined parcellations; cx and sc treated independentlypermute("maps", null_method="cornblath")— fractional transition spin; alias:"spin"; explicit choice for cortical parcellationspermute("maps", null_method="baum")— modal parcel assignment spin; alternative to cornblathpermute("maps", null_method="alexander_bloch")— original nearest-centroid spin; legacypermute("maps", null_method="burt2020")— variogram matching; works with any parcellationpermute("maps", null_method=("cornblath", "moran"))— explicit split for combined parcellations (cx=cornblath, sc=moran)permute("groups", groups=...)— group label permutation; preferred for individual subject dataAll methods produce empirical p-values stored in the NiSpace object, retrievable with
get_p_values()
Next: Notebook 6 covers multiple comparisons correction — because running 29 receptor tests at once without correction is not a great idea.